



© Techolac © Copyright 2019 - 2022, All Rights Reserved.
Internet
Best 8 Cheapest Cloud Storage Providers In 2024
Are you searching for the cheapest cloud storage possible? We show you the very best budget plan cloud storage for...
Read moreBusiness
Editor's Pick
MORE NEWS

15 Best Free OCR Software for Windows 10/11 in 2024
OCR software has revolutionized the way businesses handle their digital documents. With its advanced technology and features, OCR software enables...
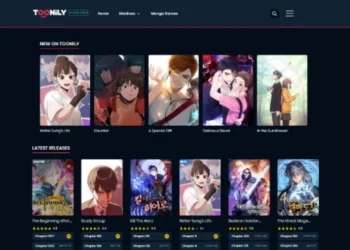
What Happened to Toonily? 24 Best Toonily Alternatives in 2024
Are you a fan of manhwa, the captivating world of Korean webcomics? Look no further than Toonily, an online platform...

Is Cowordle Free? Best 10 Games like Cowordle in 2024
Welcome to the exciting world of Cowordle, the latest craze in the realm of word puzzles. Cowordle has captivated puzzle...

Unlock the Benefits of a Goodyear Credit Card
When it comes to taking care of your vehicle, Goodyear is a trusted name that offers quality tires and exceptional...
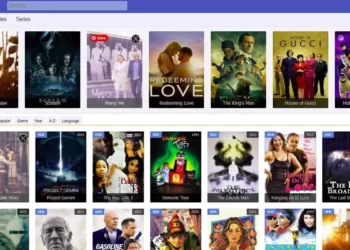
What is Goojara? Best 20 Goojara Alternatives for Watch Movies
Goojara, the ultimate platform for streaming movies and TV shows! In this comprehensive guide, we will provide you with all...

How To Fix When Discord Green Circle But No Sound
This article will show the solution when discord green circle but no sound. Nonetheless, several video game fans articulated that...

Best 5 Drift Live Chat Alternatives to Boost Customer Service
5 Drift Live Chat Alternatives to Boost Consumer Assistance. Customer assistance has been a factor since trade has been around....
Most Popular
-

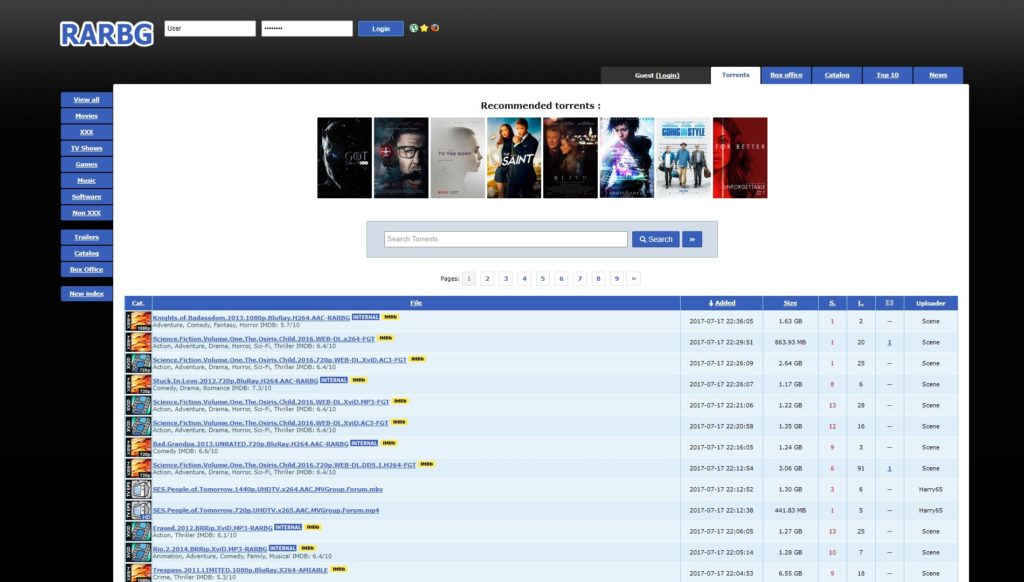
Rarbg Torrents Latest Rarbg Proxy Unblock 100% Working 2024
-
Top Best Torrent Sites 2024
-
The Pirate Bay Proxy Alternatives Mirrors Working 100%
-
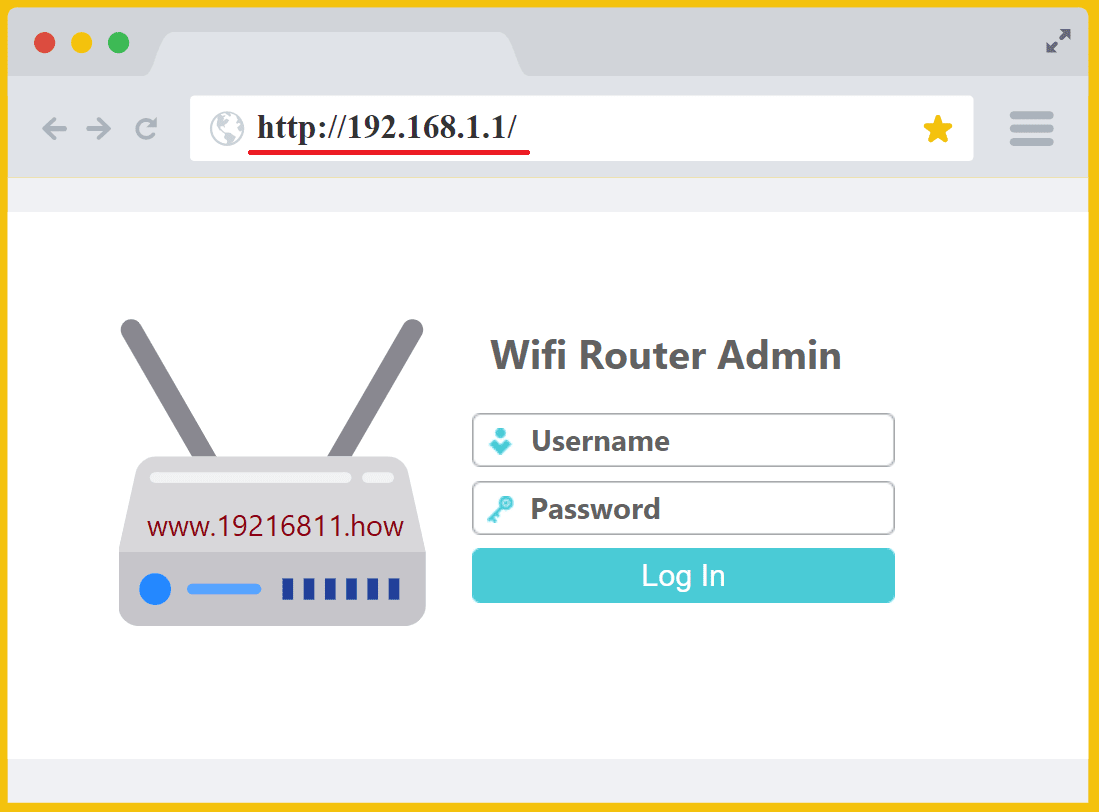
192.168.1.1 – Router Login and Administration
-
9+ Best Ipa Apps Download Sites In 2024
-
123Series Alternatives: 30 Sites to Watch Movies And TV Shows Online
-
HuraWatch Alternatives 30 Sites To Watch Movies And TV Shows Online
-
How to Recover Corrupted Outlook Email
-
10 IPTV Smarters Pro Alternatives In 2024
-
How to Remove a Credit Card From Amazon
YOU MIGHT ALSO LIKE
Editor Pick